Import CSV data¶
You can import data into the Digital Archive to create or update items from metadata in a CSV file. You can also import files to be attached to an imported item.
Caution
Importing from a CSV file involves many steps and requires the ability to use FTP to upload files to the server. You should only attempt to import after carefully reading all of the instructions on this page. Be sure you are comfortable with the process before you begin.
Import steps¶
- 1 – Prepare the import CSV file
-
The CSV file must adhere to the following:
- The CSV file must have UTF-8 encoding as explained in the next section.
- The first row must contain the source column names used in the configuration above
- Cells that contain multiple values for a single element must use a semicolon as the value delimeter.
For example, if an item has three subjects "one", "two" and "three", its Subject cell would contain
one;two;three.
UTF-8 encoding
AvantImport will only import a CSV file that has UTF-8 encoding. This is to ensure that text containing non-ASCII characters, like the
éinHébertwill import without triggering an error when saved by Omeka to the MySQL database.When saving an Excel file as CSV, choose the
CSV UTF-8option as shown below.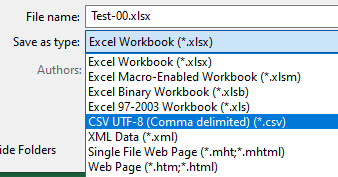
If working with CSV in a text editor like Notepad++, be sure that the file's encoding is set to UTF-8-BOM as shown below. The file must have the BOM (Byte Order Mark) in order for AvantImport to recognize it as UTF-8. Excel will insert the BOM when you choose the option shown above.
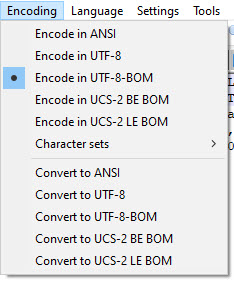
If creating a CSV file using Python, use the
utf-8-sigencoding.Excel issues
CSV data often originates in Excel. Verify that the resulting CSV file does not suffer from these issues:
- Make sure that no cells contain
#######due to a formatting problem in Excel. If you see this in the CSV data, go back to Excel and change the format of all columns to General. - If the CSV file contains a column containing dates, verify that the date format looks correct. Excel is notorious for changing dates to a different format, and for displaying dates differently than they actually exist in the CSV file.
- If Excel insists on converting dates improperly when you save the Excel as a CSV file, your only recourse may be to work with the data in a text editor like Notepad++ which is more well-behaved.
Suggestion
Before attempting to import all of your data, create a test CSV file that contains only two or three rows of CSV data. Use this file to perform all the steps on this page. Only import a file containing all of your data after achieving success with the test file.
- 2 – Upload file to be imported
-
If you will be importing files to be attached to imported items, upload all of the files into the
digitalarchive/files/importfolder using FTP. In the CSV column used to specify the files, you'll specify just the file name (with no path) and AvantImport will look for the files in theimportfolder.To indicate that a CSV column contains a file name, or a semicolon-separated list of file names, use the pseudo-element name
<files>in the Mappings field on the AvantImport configuration page. In the screenshot in step 3 below, the CSVImagescolumn will contain file names. - 3 – Configure AvantImport
-
You must configure AvantImport to tell it which columns from the CSV file that you want to import (source column names) and what the corresponding Omeka element names are for each column (target column names). It's okay if the CSV file contains columns that you don't want to import.
Follow these steps to configure the import:
- Go to the Omeka Plugins page
- Click the Configure button for
AvantImport - In the Mappings field, provide a list of source/target column pairs, separated by a colon, as shown in the screenshot below
- If the source and target names are the same, you can specify only the source name
- Click the Save Changes button
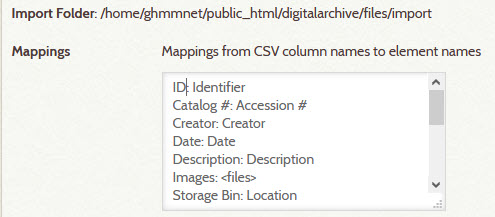
- 4 – Choose the import file
-
- Deactivate the AvantElasticsearch plugin
- Click Import CSV File in Omeka's left admin menu
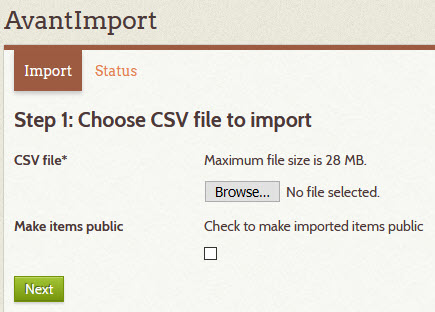
- The Step 1 page will appear
- Click the Browse button and choose a UTF-8 encoded CSV file to import
- Check the Make items public checkbox if you want the imported items to be public
- Click the Next button
- The Step 2 page will appear
If you get an error that the file cannot be imported because the column counts don't match, check to make sure there are no duplicate column names. If that's not the problem, select some columns to the right of the last column, delete them, and save the file.
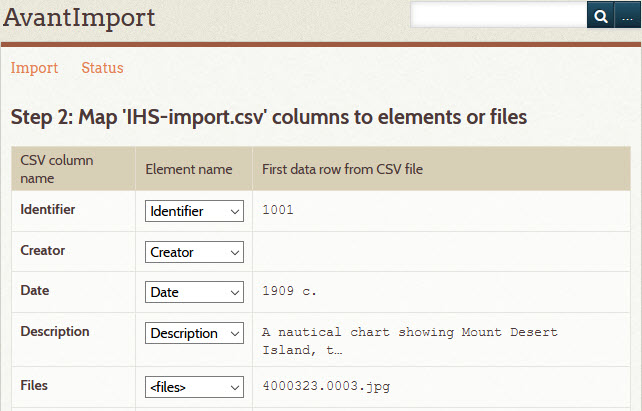
- 5 – Verify the field mappings
-
On the Step 2 page:
- Verify that the mappings are correct. To change the mappings, see step 3 above.
- Click the Import CSV file button
- The Status page will appear and the import will begin
- Refresh the browser every so often until the status is
Completed
- 6 – Verify that the import worked correctly
-
The screenshot below shows that the import completed, but three records were skipped.
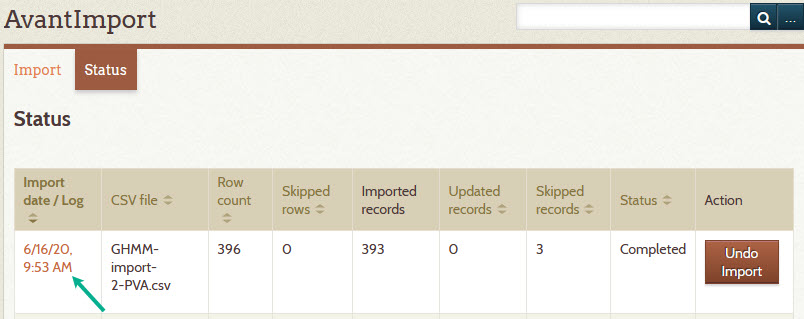
Click on the import date/log to see why the records were skipped. The import log appears showing details about the import process. The 4th row on the next screenshot shows that one of the file names in the CSV file was not readable or does not exist. The 5th rows says that the record on row #121 was skipped.
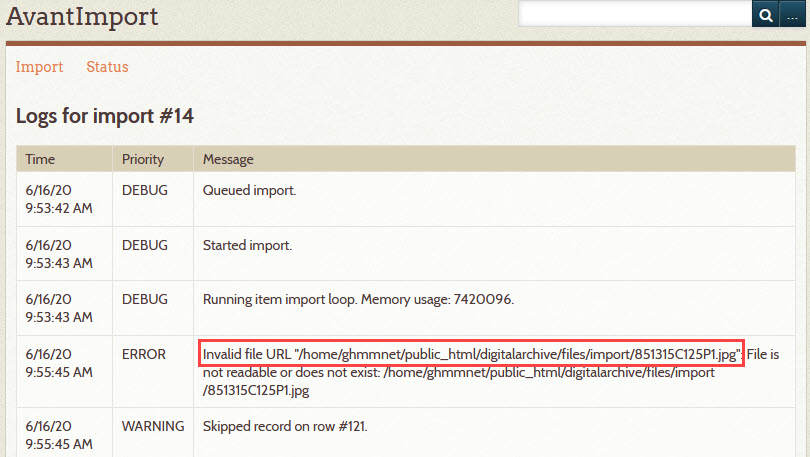
The row # in the message is the row number in the CSV file. For example, row #1 is the header row in the CSV file and row #2 is the first item to be imported.
- 7 – Fix import errors
-
To import the skipped rows:
- Determine the cause of the problem.
- Often it's a misspelling of a file name, or even a difference in letter
casing. For example, if the CSV file refers to a file named
1234.jpg, but the actual file name is1234.JPG, the file won't be found. - The presence of a
#in a file name seems to cause the import logic to truncate the name before the#which then causes a file name mismatch. - The presence of
/\in column text causes the logic to skip that row and one or more subsequent rows. The error reports 1 skipped row and does not say which row.
- Often it's a misspelling of a file name, or even a difference in letter
casing. For example, if the CSV file refers to a file named
- Make a copy of the import file with all the rows removed except the offending row(s). A good way to do this is to use a color to highlight the bad rows, then delete all the rows except for the highlighted ones. If you simply start deleting the good rows, the row numbers in the error report will no longer match the rows in the CSV file.
- Fix the row data and/or the file name
- Reimport the copy of the import file that contains only the skipped rows
- Repeat this process as necessary until all the data is imported.
- Determine the cause of the problem.
- 8 – Rebuild the Site Terms table
-
Because the import occurs with Elasticsearch disabled, which in turn disables the Common Vocabulary feature, you need to rebuild the site terms table.
- Activate the AvantElasticsearch plugin
- Choose Vocabulary Editor from the left admin menu
- Click the Rebuild Site Terms table button
- Click OK on the confirmation dialog
- When the build completes, the page will reload and show the updated site terms
Note
You must rebuild the site terms table before rebuilding the Elasticsearch indexes. If you reindex first, you'll see
UNTRACKEDin the Refine Your Search panel on any new terms that came from the import that were not already in the site vocabulary. - 9 – Rebuild the Elasticsearch indexes
- Because the import occurs with Elasticsearch disabled, you need to rebuild the site's Elasticsearch indexes. Be sure to do this after you rebuild the site terms table.
- 10 – Cleanup the import folder
- Once the import is successful, use FTP to delete the files from the
digitalarchive/files/importfolder on the server.